A quadratic arithmetic program is an arithmetic circuit, specifically a Rank 1 Constraint System (R1CS) represented as a set of polynomials. It is derived using Lagrange interpolation on a Rank 1 Constraint System. Unlike an R1CS, a Quadratic Arithmetic Program (QAP) can be tested for equality in time via the Schwartz-Zippel Lemma.
Key ideas
In the chapter on the Schwartz-Zippel Lemma, we saw that we can test if two vectors are equal in time by converting them to polynomials, then running the Schwartz-Zippel Lemma test on the polynomials. (To clarify, the test is time, converting the vectors to polynomials creates overhead).
Because a Rank 1 Constraint System is entirely composed of vector operations, we aim to test if
holds in time instead of time (where is the number of rows in , , and ).
But before we do that, we need to understand some key properties of the relationship between vectors and polynomials that represent them.
For all math here, we assume we are working in a finite field, but we skip the notation for succinctness.
Homomorphisms between vector addition and polynomial addition
Vector addition is homomorphic to polynomial addition
If we take two vectors, interpolate them with polynomials, then add the polynomials together, we get the same polynomial as if we added the vectors together and then interpolated the sum vector.
Spoken more mathematically, let be the polynomial resulting from Lagrange interpolation on the vector using as the values, where is the length of . The following is true:
In other words, the polynomials resulting from interpolating vectors and are the same as the polynomials resulting from interpolating the vectors .
Worked example
Let and interpolates or the vector and interpolates .
The sum of the vectors is and it is clear that interpolates that. Let .
Testing the math in Python
Unit testing a proposed mathematical identity doesn’t make it true, but it does illustrate what is happening. The reader is encouraged to try out a few different vectors to see that the identity holds.
When we say “multiply a vector by 3” we are really saying “add the vector to itself three times”. Since we are only working in finite fields, we don’t concern ourselves with the interpretation of scalars such as “0.5”
We can think of both vectors under element-wise addition (in a finite field) and polynomials under addition (also in a finite field) as groups.
The most important takeaway from this chapter is
The group of vectors under addition in a finite field is homomorphic to the group of polynomials under addition in a finite field.
This is critical because vector equality testing takes time, but polynomial equality testing takes time.
Therefore, whereas testing R1CS equality took time, we can leverage this homomorphism to test the equality of R1CSs in time.
This is what a Quadratic Arithmetic Program is.
A Rank 1 Constraint System in Polynomials
Consider that matrix multiplication between a rectangular matrix and a vector can be written in terms of vector addition and scalar multiplication.
For example, if we have a matrix and a 4 dimensional vector , then we can write the matrix multiplication as
We typically think of the vector “flipping” and doing an inner product (generalized dot product) with each of the rows, i.e.
However, we could instead think of splitting matrix into a bunch of vectors as follows:
and multiplying each vector by a scalar from the vector :
We have expressed matrix multiplication between and purely in terms of vector addition and scalar multiplication.
Because we established earlier that the group of vectors under addition in a finite field is homomorphic to the group of polynomials under addition in a finite field, can express the computation above in terms of polynomials that represent the vectors.
Succintly testing that
Suppose we have matrix and such that
and vectors and
We want to test if
is true.
Obviously we can carry out the matrix arithmetic, but the final check will require comparisons, where is the number of rows in and . We want to do it in time.
First, we convert the matrix multiplication and to the group of vectors under addition:
We now want to find the homomorphic equivalent of
in the polynomial group.
Let’s convert each of the vectors to polynomials over the values :
We will invoke some Python to compute the Langrage interpolation:
The final assert statement is able to test if doing a single comparison instead of .
R1CS to QAP: Succinctly testing that
Since we know how to test of succinctly, can we also test if succinctly?
The matrices have columns, so let’s break each of the matrices into column vectors and interpolate them on to produce polynomials each.
Let be the polynomials that interpolate the column vectors of .
Let be the polynomials that interpolate the column vectors of .
Let be the polynomials that interpolate the column vectors of .
Without loss of generality, let’s say we have 4 columns () and three rows ().
Visually, this can be represented as
Since multiplying a column vector by a scalar is homomorphic to multiplying a polynomial by a scalar, each the polynomials can be multiplied by the respective element in the witness.
For example,
becomes
Observe that the final result is a single polynomial with degree at most , since each have degree at most .
This follows from how we constructed them: each column of has entries, and interpolating through points via Lagrange interpolation produces a polynomial of degree at most .
In the general case, can be written as
after converting each of the columns to polynomials.
Using the same steps above, each matrix-witness product in the R1CS can be transformed as
Since each of the sum terms produces a single polynomial, we can write them as:
Why interpolate all the columns?
Because of the homomorphisms and , if we compute as we get the same result as applying Lagrange interpolation to the columns of and then multiplying each of the polynomials by the respective element in and summing the result.
Spoken another way,
So why not just compute a single Lagrange interpolation instead of ?
We need to make a distinction between who is using the QAP. The verifier (and the trusted setup which we will cover later) do not know the witness and thus cannot compute . This is an optimization the prover can make, but other parties in the ZK protocol cannot make use of that optimization.
All parties involved need to have a common agreement on the QAP – the polynomial interpolations of the matrices before any proofs and verifications are done.
Polynomial degree imbalance
However, we can’t simply express the final result as
because the degrees won’t match.
Multiplying two polynomials together results in a product polynomial whose degree is the sum of the degrees of the two polynomials being multiplied together.
Because each of , , and will have degree , will generally have degree and will have degree , so they won’t be equal even though the underlying vectors they multiplied are equal.
This is because the homorphisms we established earlier only make claims about vector addition, not Hadamard product.
However, the vector that interpolates, i.e.
is the same as the vector that interpolates, i.e.
In other words
Although the “underlying” vectors are equal, the polynomials that interpolate them are not equal.
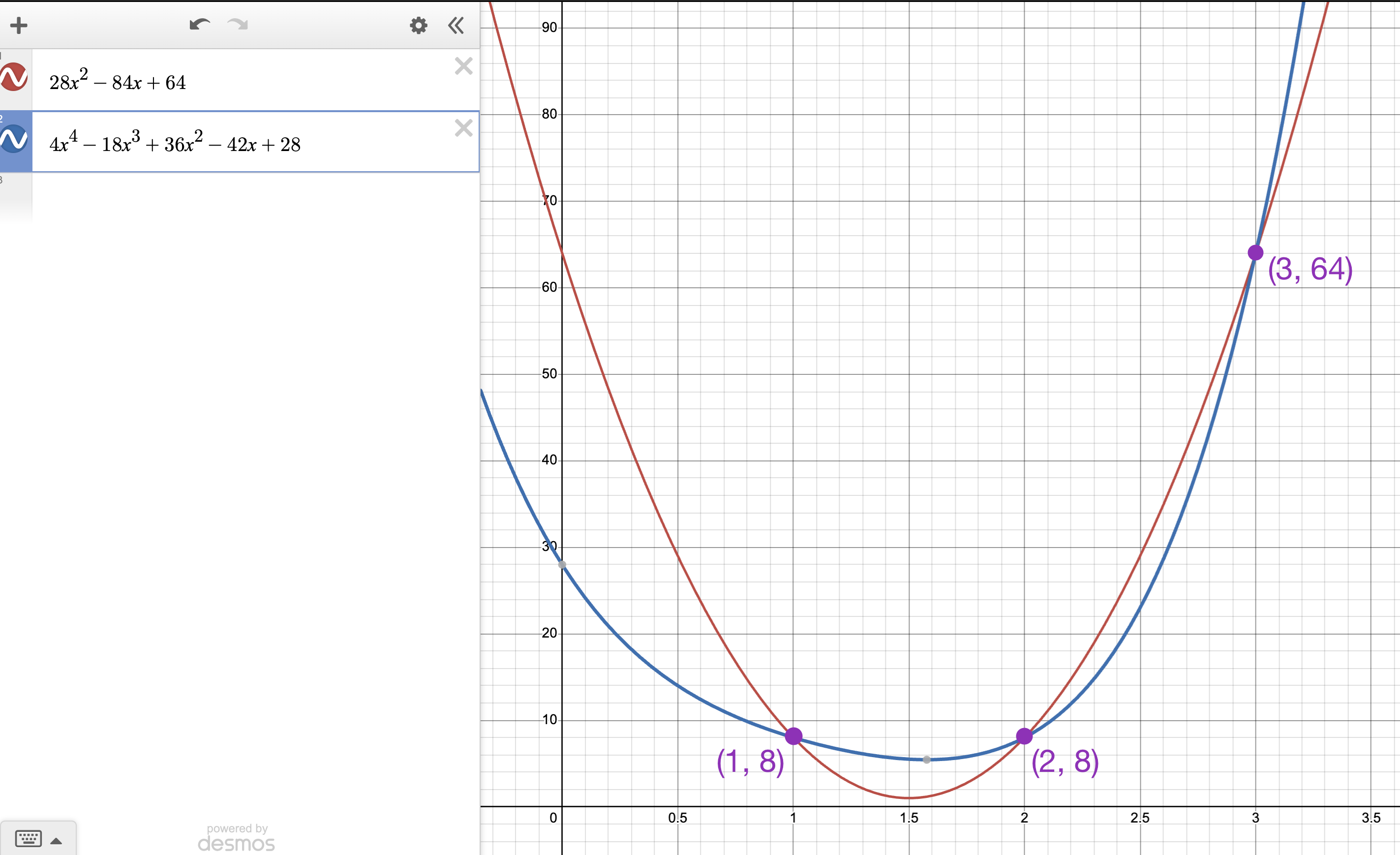
Example of underlying equality
Let’s say that is the polynomial that interpolates
and is the polynomial that interpolates
If we treat as interpolating the vector and as interpolating the vector , then we can see that their product polynomial interpolates the Hadamard product of the two vectors. The Hadamard product of and is .
If we multiply and together, we get .
We can see in the plot below that the product polynomial interpolates the Hadamard product of the two vectors.
So how can we “make” equal to if they interpolate the same values over ?
Interpolating the vector
If , then .
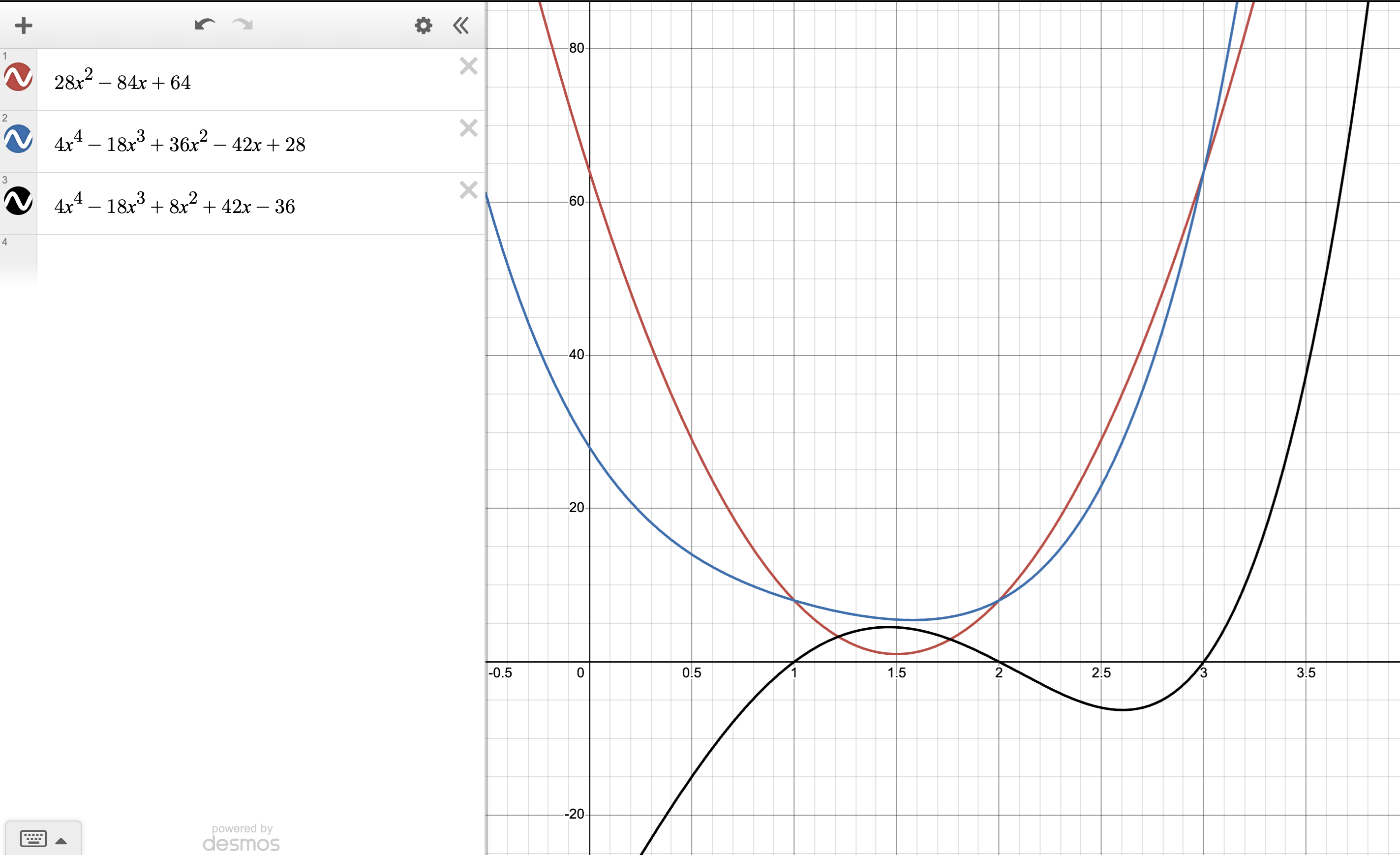
Instead of interpolating with Lagrange interpolation and getting (remember Lagrange interpolation finds the lowest degree interpolating polynomial), we can use a higher degree polynomial that will balance out the mismatch in degrees.
For example, the black polynomial () in the image below interpolates :
Now, since is a valid interpolation of , we can write our original
and the equation will be balanced!
was simply computed as (the blue polynomial minus red polynomial)
However, we can’t just let the prover pick any, otherwise they could pick a that balances and even if they do not interpolate the same vector ( in our example). The prover has too much flexibility in choosing . Specifically, we want to require to have roots at – that is, to interpolate the vector. That way, the polynomial transformation of still respects the underlying vectors.
To restrict their choice of , we can use the following theorem:
The union of roots of the polynomial product
Theorem: If and has set of roots and has set of roots , then has roots .
Example
Let and . Then has roots .
We can use the theorem above to enforce that has roots at .
Forcing to be the zero vector
We decompose into where is the polynomial
then any polynomial multiplied with will also be the zero vector, as it must have roots at .
Therefore, we will replace with in our equation.
Thus, our equality will become
We can compute using basic algebra:
QAP End-to-end
Suppose we have an R1CS with matrices , , and and witness vector .
The matrices have columns and rows where and .
That is, , , and are as follows:
And witness vector is
We split each of the matrices into column vectors and interpolate them on to produce polynomials each.
Each of the matrix-vector products , , and are homorphically equivalent the following polynomials:
In our case, will be
and will be
The final formula for a QAP representation of the original R1CS is
Final formula for a QAP
A QAP is the following formula:
Where , , and are polynomials that interpolate the columns of , , and respectively, is , where is the number of rows in , , and , and is
Succinct zero knowledge proofs with Quadratic Arithmetic Programs
Suppose we had a way for the verifier to send a random value to the prover and the prover would respond with
The verifier could check that and accept that the prover has a valid witness that satisfies both the R1CS and the QAP.
However, this would require the verifier to trust that the prover is evaluating the polynomials correctly, and we don’t have a mechanism to force the prover to do so.
In the next chapter, we will show Python code to convert an R1CS to a QAP based on our discussion in this chapter.
Then we will discuss trusted setups to begin to tackle the problem of how to get the prover to evaluate the polynomials honestly.